Processing big spatial data in the Cloud, using distributed computing with GIS server software, can reduce the time and computer hardware capacity needed.
Users of Big Spatial Data will know that working with national scale datasets can be challenging when relying on desktop software.
On a desktop, big datasets can take days to prepare and process. Analytical and visualisation tasks can also be overwhelmed by the amount of data. This is a problem particularly when the outcomes of tasks are time sensitive and results are required as soon as possible.
The economies of crunching big data with server technology are substantial. Working with big data on a desktop is inefficient, with more time being required by highly skilled staff to run tasks, and workstations not being operable while processes are run.
Large organisations working with big spatial datasets, including local, state and federal government departments needing to store, process, analyse and visualise data to work more effectively can run into problems relying on desktop hardware.
By using distributed computing, multiple tasks can be run in parallel remotely on a server and the workstation can used as normal.
Data is processed once then supplied to multiple staff across an organisation. This saves the time of multiple staff running the same process.
Distributed computing supports agile work environments, allowing fail-fast research groups to rapidly test different processes. By being able to analyse and visualise data more rapidly, analysts are able to test out more processes.
In this blog, I describe how GIS technology deployed on Microsoft Azure can assess the quality of Australian census blocks using address data stored on Amazon Web Services.
Australia’s Geocoded National Address File (G-NAF) is the foundation geocoded address database of all physical addresses in Australia. It contains over 13 million records and is several gigabytes in size.
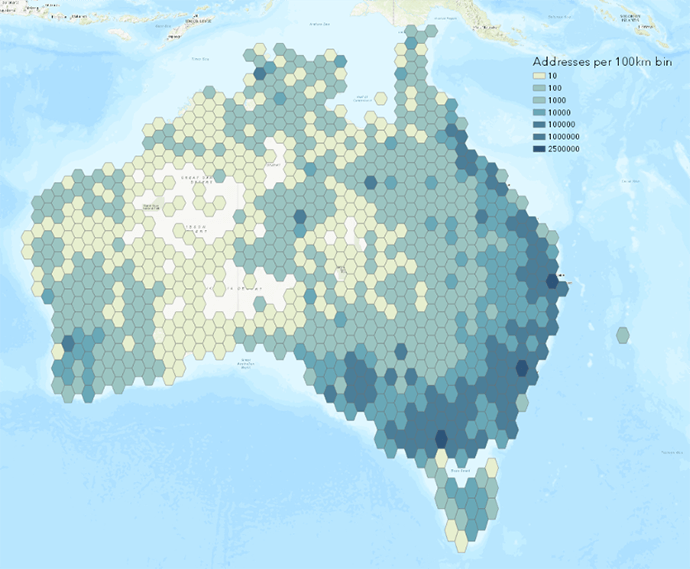
Address databases like G-NAF are big datasets that are complex to create, frequently updated and require skill to process.
With the G-NAF, mesh blocks are the smallest geographic area defined by the Australian Bureau of Statistics for which Census data are available. They broadly identify land use categories such as residential, commercial, primary production and parks, etc.
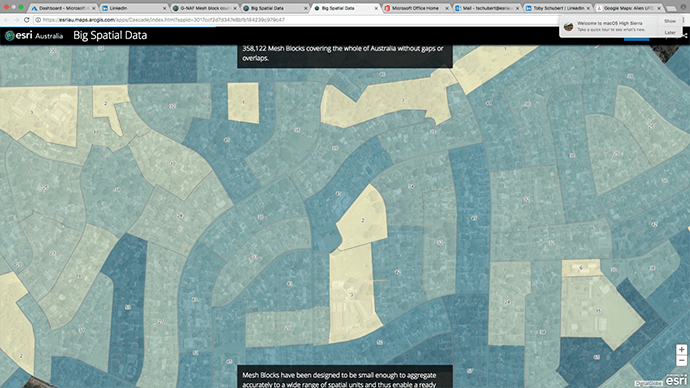
The 2016 Australian Statistical Geography Standard (ASGS) contains 358,122 mesh blocks covering the whole of Australia without gaps or overlaps.
They have been designed to be small enough to aggregate accurately to a wide range of spatial units and thus enable a ready comparison of statistics between geographical areas, and large enough to protect against accidental disclosure; most residential blocks contain approximately 30 to 60 dwellings.
The map below shows the number of G-NAF addresses in each mesh block. You can see in this area of Sydney most have less than 60 dwellings; but there are some with well over 60, which occurs when there is an apartment with many addresses in a small area. There are also blocks with less than 30; these usually contain addresses for public places such as schools.
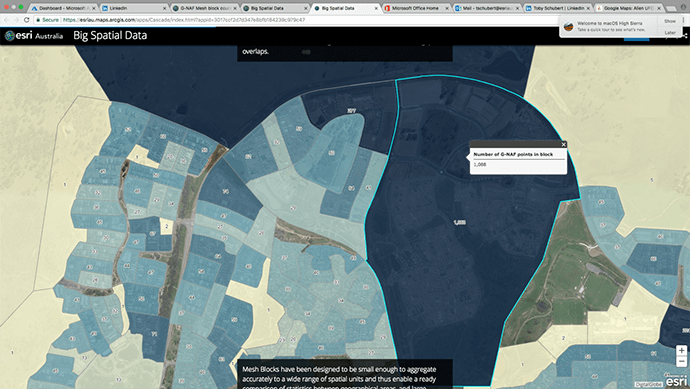
The following map shows a block in Canberra containing over 1,000 addresses that were extracted from the more up-to-date G-NAF dataset. The DigitalGlobe basemap imagery shows a new housing estate that must have been completed after the mesh blocks had been created.
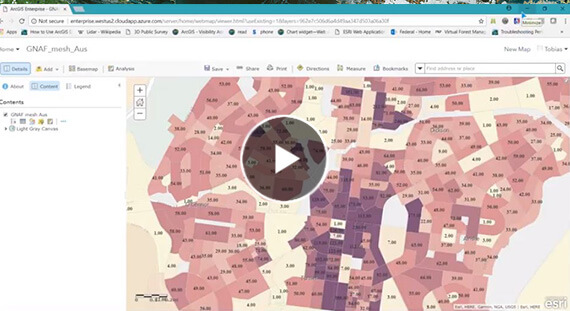
The results shown in the maps were attained by processing these databases in the Cloud.
By shifting geoprocessing to the Cloud, organisations can save hours of processing time. This example would have taken four hours to process using traditional desktop hardware. Using the Cloud, it took only 17 minutes.
The mesh block and address databases are so large that processing such databases with desktop hardware can be both time consuming and expensive.
This is a problem frequently encountered by organisations in possession of address information, from local government to marketing organisations.
By leveraging the Cloud – using ArcGIS deployed on Microsoft Azure – to perform distributed computing, the results for the number of each of the 13 million addresses in every one of the 350,000 mesh blocks can be calculated in Esri ArcGIS deployed on Microsoft Azure … in 17 minutes.
For this example, the aggregation geoprocessing task was set to run on the Cloud managed from a desktop with a fraction of the computational power required. Once the task was complete, the Cloud-based server was switched off.
Although this task was run in Azure, the address data was accessed from storage in an Amazon Web Services S3 bucket, demonstrating how distributed processing can be performed with ArcGIS across multiple Cloud services.
This procedure was run using ArcGIS GeoAnalytics Server on ArcGIS Enterprise accessed via ArcGIS Pro. This Server role was created for high performance analytics and real-time, big data processing, ideal for hotspot analysis, pattern analysis, aggregation and visualisation of databases.
To find out more about using distributed Cloud computing to handle big spatial data, call 1800 870 750 or send us an email.
